本档旨在从底层 AOSP 源码视角,拆解 JankStats 捕获的每一项耗时指标的物理来源,并精确到具体的类、函数及源码路径。
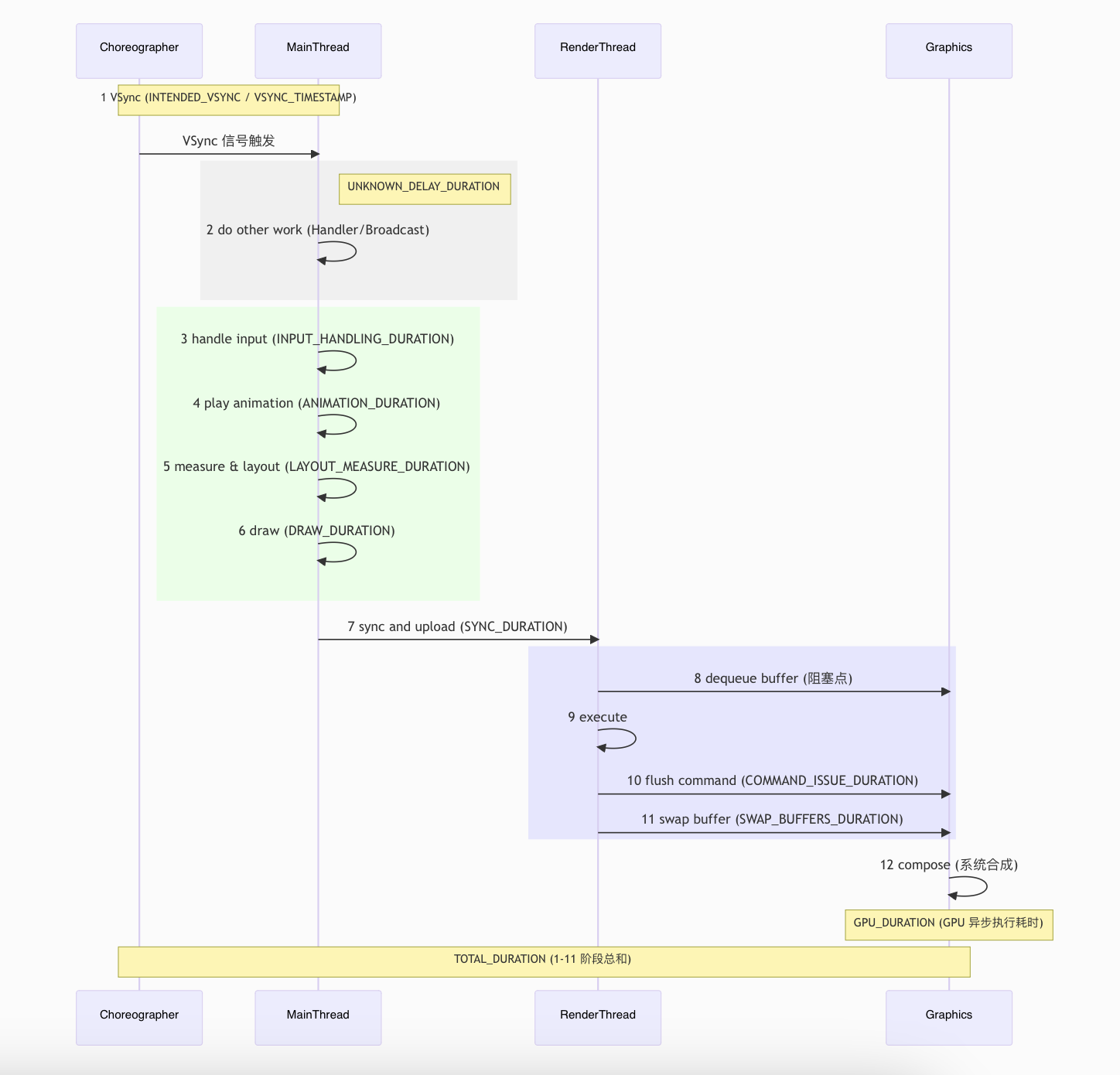
全链路耗时概览图 一帧的产生经历了:Vsync 信号(Choreographer) -> UI 线程处理(MainThread) -> Sync 同步 -> RenderThread 处理 -> GPU 渲染 -> Buffer 交换 。
mermaid 代码
sequenceDiagram
participant C as Choreographer
participant M as MainThread
participant R as RenderThread
participant G as Graphics
Note over C, M: 1 VSync (INTENDED_VSYNC / VSYNC_TIMESTAMP)
C->>M: VSync 信号触发
rect rgb(240, 240, 240)
Note right of M: UNKNOWN_DELAY_DURATION
M->>M: 2 do other work (Handler/Broadcast)
end
rect rgb(230, 255, 230)
M->>M: 3 handle input (INPUT_HANDLING_DURATION)
M->>M: 4 play animation (ANIMATION_DURATION)
M->>M: 5 measure & layout (LAYOUT_MEASURE_DURATION)
M->>M: 6 draw (DRAW_DURATION)
end
M->>R: 7 sync and upload (SYNC_DURATION)
rect rgb(230, 230, 255)
R->>G: 8 dequeue buffer (阻塞点)
R->>R: 9 execute
R->>G: 10 flush command (COMMAND_ISSUE_DURATION)
R->>G: 11 swap buffer (SWAP_BUFFERS_DURATION)
end
G->>G: 12 compose (系统合成)
Note over G: GPU_DURATION (GPU 异步执行耗时)
Note over C, G: TOTAL_DURATION (1-11 阶段总和)
流程详细说明与 FrameMetrics 参数对应
流程编号
流程名称
详细说明
对应 FrameMetrics 参数
1 VSync Choreographer 接收到硬件 VSync 信号,触发主线程。INTENDED_VSYNC_TIMESTAMP (预期) / VSYNC_TIMESTAMP (实际)
2 do other work 主线程在处理 UI 前执行的其他任务(如 Handler 消息、广播)。
UNKNOWN_DELAY_DURATION
3 handle input 处理触摸、按键等输入事件。
INPUT_HANDLING_DURATION
4 play animation 执行属性动画、帧动画等。
ANIMATION_DURATION
5 measure & layout 对 View 树进行测量和布局,确定每个控件的大小和位置。
LAYOUT_MEASURE_DURATION
6 draw 录制绘制指令 (DisplayList),将 Canvas 绘制转化为 Native 指令。
DRAW_DURATION
7 sync and upload 将主线程录制的绘制信息和资源(如 Bitmap)同步到渲染线程。
SYNC_DURATION
8 dequeue buffer 渲染线程从 BufferQueue 申请缓冲区。此处是著名的阻塞点。
(包含在 TOTAL_DURATION 中,或由 DequeueBufferDuration 统计)
9-10 execute & flush 渲染线程回放绘制指令,调用 GPU 渲染并刷新指令队列。
COMMAND_ISSUE_DURATION
11 swap buffer 将渲染完成的 Buffer 提交给 SurfaceFlinger。
SWAP_BUFFERS_DURATION
12 compose SurfaceFlinger 进行画面合成并显示到屏幕。(属于系统层,不计入应用内耗时)
FrameMetrics 详细指标参考表
FrameMetrics 的常量值
含义
可能导致耗时多久的情况
UNKNOWN_DELAY_DURATIONUI 线程延迟处理绘制任务的耗时
主线程消息队列中正在执行的非绘制任务耗时太久,导致开始执行绘制任务太晚
INPUT_HANDLING_DURATION输入事件处理函数的耗时
点击事件耗时太久
ANIMATION_DURATION动画回调函数的耗时
动画太多或者回调函数耗时太久
LAYOUT_MEASURE_DURATION整个 View 树的测量和布局的耗时
布局层级复杂,频繁改变尺寸或位置(比如复杂的属性动画)
DRAW_DURATION布局绘制函数的耗时
draw/onDraw 里执行了耗时操作
SYNC_DURATION主线程同步 DisplayList 到 RenderThread 的耗时
过度绘制,导致要更新的 DisplayList 过多
COMMAND_ISSUE_DURATIONRenderThread 发送绘制命令到 GPU 的耗时
绘制内容复杂
SWAP_BUFFERS_DURATION将绘制的 buffer 交换到前台显示的耗时
—
TOTAL_DURATION绘制一帧的总耗时
前面任意一个阶段耗时,最终这个值都会变大
FIRST_DRAW_FRAME这帧是否是当前窗口的第一帧
—
INTENDED_VSYNC_TIMESTAMP预期接收到 VSync 信号(也就是这帧开始执行)的时间戳
—
VSYNC_TIMESTAMP真正接收到 VSync 信号的时间
主线程的耗时任务太多,会导致主线程响应 VSync 信号过慢
GPU_DURATIONGPU 完成这帧绘制的耗时
—
其他核心参数解析
TOTAL_DURATIONGPU_DURATIONDEADLINETOTAL_DURATION > DEADLINE,通常意味着发生了卡顿。FIRST_DRAW_FRAME
Android 帧绘制耗时全链路溯源 核心指标:UNKNOWN_DELAY_DURATION(未知延迟时长)
物理意义 :从系统产生 Vsync 信号到 UI 线程真正开始执行 doFrame 任务的时间差。精确路径 :
起点 :DisplayEventReceiver 收到底层信号,通过 JNI 回调发送消息到 Looper。
源码:frameworks/base/core/java/android/view/DisplayEventReceiver.java
关键函数 :Choreographer$FrameDisplayEventReceiver.run() 被 Looper 唤醒,调用 doFrame。
源码:frameworks/base/core/java/android/view/Choreographer.java
终点 :Choreographer.doFrame() 开始执行。
计算逻辑 :UNKNOWN_DELAY = FrameInfo[HANDLE_INPUT_START] - FrameInfo[INTENDED_VSYNC]解析 :
INTENDED_VSYNC :理想的帧开始时间戳(Vsync 信号发生的时刻)。HANDLE_INPUT_START :UI 线程 Looper 实际分发到该渲染消息并开始处理的时刻。
参数价值 :反映 UI 线程的消息队列积压情况 。如果此值大,说明 UI 线程正在执行非 UI 的耗时任务(如长耗时的 Handler 消息或过重的业务逻辑)。
第二阶段:UI 线程的奔跑 (Logic & Construction) 核心指标:INPUT_HANDLING(输入处理) + ANIMATION(动画) + LAYOUT_MEASURE(布局测量) + DRAW(绘制)
物理意义 :UI 线程执行业务逻辑并构建绘制指令的过程。精确路径 :
Input Handling :Choreographer.doCallbacks(Choreographer.CALLBACK_INPUT) -> InputEventReceiver.consumeEvents()。
源码:frameworks/base/core/java/android/view/InputEventReceiver.java
Animations :Choreographer.doCallbacks(Choreographer.CALLBACK_ANIMATION) -> 执行所有已注册 of the ValueAnimator 等回调。Layout & Measure :Choreographer.doCallbacks(Choreographer.CALLBACK_TRAVERSAL) -> ViewRootImpl.performTraversals()。
performTraversals 核心步骤解析 :
relayoutWindow :通过 IPC 与 WindowManagerService 通信,获取或调整 Surface,确定窗口的物理大小(Frame Size)。**performMeasure()**:从顶层 DecorView 开始深度优先遍历 View 树。每个 View 根据父容器的 MeasureSpec 计算自己的 MeasuredWidth 和 MeasuredHeight。
**performLayout()**:根据测量结果确定 View 在窗口中的最终位置坐标(Left, Top, Right, Bottom),并触发 View 的 onLayout()。
**performDraw()**:启动绘制阶段,将 View 树的视觉信息转化为渲染指令。
源码:frameworks/base/core/java/android/view/ViewRootImpl.java
**Draw (Recording)**:ViewRootImpl.performDraw() -> ThreadedRenderer.draw() -> View.updateDisplayListIfDirty()。
源码:frameworks/base/core/java/android/view/ThreadedRenderer.java
注意 :此处是在录制指令到 DisplayList,而非真正渲染。
参数价值 :反映 布局复杂度 (Over-nesting) 和 主线程计算压力 。
第三阶段:交接棒 (Handoff / Sync) 核心指标:SYNC_DURATION(同步时长)
物理意义 :UI 线程阻塞等待,将绘制指令和 Bitmap 资源同步给 RenderThread。精确路径 :
Java 端入口 :ThreadedRenderer.nSyncAndDrawFrame() (JNI 调用)。
源码:frameworks/base/core/java/android/view/ThreadedRenderer.java
Native 端核心 :CanvasContext::prepareTree()。
源码:frameworks/base/libs/hwui/renderthread/CanvasContext.cpp
资源上传 :在此阶段,新创建的 Bitmap 会被上传到 GPU 纹理缓存。
计算逻辑 :记录从 UI 线程发起同步请求到 RenderThread 成功接收并完成资源拷贝,且 UI 线程被唤醒的时间。参数价值 :Bitmap 优化的核心指标 。如果 SYNC 耗时高,通常是由于该帧上传了过大的 Bitmap 或触发了大量的资源回收与重新分配。
第四阶段:渲染线程的冲刺 (Recording & Issue) 核心指标:COMMAND_ISSUE_DURATION(指令发布时长)
物理意义 :RenderThread 将 DisplayList 转换为真正的 GPU 指令(OpenGL/Vulkan)并提交给驱动。精确路径 :
RenderThread 循环 :RenderThread::threadLoop()。
源码:frameworks/base/libs/hwui/renderthread/RenderThread.cpp
核心执行 :CanvasContext::draw() 调用渲染管线。渲染管线 :SkiaPipeline::renderFrame() (Android 8.0+ 默认使用 Skia)。
源码:frameworks/base/libs/hwui/pipeline/skia/SkiaPipeline.cpp
参数价值 :反映 绘制指令的复杂程度 。DrawCalls 越多、Path 路径越复杂、或者使用了复杂的 Shader,此项耗时越高。
第五阶段:终点线 (GPU & Swap) 核心指标:SWAP_BUFFERS_DURATION(缓冲区交换时长)
物理意义 :RenderThread 调用 eglSwapBuffers 后,等待 GPU 渲染完成并交换缓冲区的阻塞时间。精确路径 :
核心函数 :CanvasContext::swapBuffers()。底层调用 :EglManager::swapBuffers() -> eglSwapBuffers()。
源码:frameworks/base/libs/hwui/renderthread/EglManager.cpp
系统反馈 :底层 SurfaceFlinger 消费 Buffer 的速度(涉及 BufferQueue)。
解析 :如果 GPU 还没算完,或者系统显示队列已满(存在背压),此调用会阻塞 RenderThread,直到有可用的 Buffer。面试价值 :反映 GPU 渲染压力 (Overdraw) 或 系统三重缓冲 (Triple Buffering) 的饱和度。也是衡量 SurfaceFlinger 消费压力的关键点。
第六阶段:最终审判 (Judgment) 核心指标:TOTAL_DURATION(总耗时) & frameOverrunNanos(帧超时时间) (API 31+)
物理意义 :一帧从计划开始到最终出屏全链路总耗时及其与截止日期的偏离量。精确路径 :
Java 层 :android.view.FrameMetrics
源码:frameworks/base/core/java/android/view/FrameMetrics.java
Native 层 :google::hwui::FrameInfo
源码:frameworks/base/libs/hwui/FrameInfo.cpp
卡顿判定准则 :
经典准则 :TOTAL_DURATION > 16.6ms (针对 60Hz)。**JankStats 准则 (API 31+)**:frameOverrunNanos > 0。即该帧物理上错过了 VSync 的 Deadline(最准确的掉帧判定)。
Q&A
Q:如果 UI 线程只用了 2ms,为什么还是掉帧了?
A :通过 FrameMetrics 分析,可能是 UNKNOWN_DELAY 极大(消息队列排队严重)或 SWAP_BUFFERS 阻塞严重(GPU 瓶颈或渲染队列满了)。
Q:SYNC_DURATION(同步时长)过高怎么排查?
A :重点检查该帧是否有大图加载、ImageView 设置了巨大的 Bitmap,或者是否在 onDraw 之外频繁触发了硬件资源更新。
Q:为什么硬件加速下,RenderThread 卡顿会影响 UI 线程?
A :因为 SYNC 阶段是同步的。UI 线程必须在 CanvasContext::prepareTree 期间等待 RenderThread 接收数据,只有等 RenderThread “接手”成功后,UI 线程才能继续处理下一个 Vsync。
Android 帧绘制耗时全链路源码溯源 本文档详细记录了从 Java 层到 Native 层的 Android 帧刷新全链路核心函数(Android 15),并对源码关键逻辑进行了中文注释。
Java 层:UI 线程任务调度 frameworks/base/core/java/android/view/
帧回调起点:Choreographer.doFrame() 这是主线程响应 VSYNC 信号的总入口。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 void doFrame (long frameTimeNanos, int frame, DisplayEventReceiver.VsyncEventData vsyncEventData) { final long startNanos; final long frameIntervalNanos = vsyncEventData.frameInterval; boolean resynced = false ; try { FrameTimeline timeline = mFrameData.update(frameTimeNanos, vsyncEventData); if (Trace.isTagEnabled(Trace.TRACE_TAG_VIEW)) { Trace.traceBegin(Trace.TRACE_TAG_VIEW, "Choreographer#doFrame " + timeline.mVsyncId); } synchronized (mLock) { if (!mFrameScheduled) { return ; } long intendedFrameTimeNanos = frameTimeNanos; startNanos = System.nanoTime(); final long jitterNanos = startNanos - frameTimeNanos; if (jitterNanos >= frameIntervalNanos) { long lastFrameOffset = jitterNanos % frameIntervalNanos; frameTimeNanos = startNanos - lastFrameOffset; final long skippedFrames = jitterNanos / frameIntervalNanos; if (skippedFrames >= SKIPPED_FRAME_WARNING_LIMIT) { Log.i(TAG, "Skipped " + skippedFrames + " frames! 应用程序可能在主线程做了太多工作。" ); } timeline = mFrameData.update(frameTimeNanos, mDisplayEventReceiver, jitterNanos); resynced = true ; } mFrameInfo.setVsync(intendedFrameTimeNanos, frameTimeNanos, vsyncEventData.preferredFrameTimeline().vsyncId, vsyncEventData.preferredFrameTimeline().deadline, startNanos, vsyncEventData.frameInterval); mFrameScheduled = false ; mLastFrameTimeNanos = frameTimeNanos; } AnimationUtils.lockAnimationClock(frameTimeNanos / TimeUtils.NANOS_PER_MS, timeline.mExpectedPresentationTimeNanos); mFrameInfo.markInputHandlingStart(); doCallbacks(Choreographer.CALLBACK_INPUT, frameIntervalNanos); mFrameInfo.markAnimationsStart(); doCallbacks(Choreographer.CALLBACK_ANIMATION, frameIntervalNanos); doCallbacks(Choreographer.CALLBACK_INSETS_ANIMATION, frameIntervalNanos); mFrameInfo.markPerformTraversalsStart(); doCallbacks(Choreographer.CALLBACK_TRAVERSAL, frameIntervalNanos); doCallbacks(Choreographer.CALLBACK_COMMIT, frameIntervalNanos); } finally { AnimationUtils.unlockAnimationClock(); Trace.traceEnd(Trace.TRACE_TAG_VIEW); } }
补充 VsyncEventData
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 #pragma once #include <android/gui/FrameTimelineInfo.h> #include <array> namespace android::gui { struct VsyncEventData { static constexpr int64_t kFrameTimelinesCapacity = 7 ; int64_t frameInterval; uint32_t preferredFrameTimelineIndex; uint32_t frameTimelinesLength; struct alignas (8 ) FrameTimeline { int64_t vsyncId; int64_t deadlineTimestamp; int64_t expectedPresentationTime; } frameTimelines[kFrameTimelinesCapacity]; int64_t preferredVsyncId () const; int64_t preferredDeadlineTimestamp () const; int64_t preferredExpectedPresentationTime () const; }; struct ParcelableVsyncEventData : public Parcelable { VsyncEventData vsync; status_t readFromParcel (const Parcel*) override; status_t writeToParcel (Parcel*) const override; }; }
接过来自底层 DisplayEventReceiver.cpp 传上来的“发令枪响时间” (frameTimeNanos)。
任务分发:Choreographer.doCallbacks() 这是 Choreographer 内部用于依次执行各阶段任务(输入、动画、遍历、提交)的核心逻辑。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 void doCallbacks (int callbackType, long frameIntervalNanos) { CallbackRecord callbacks; long frameTimeNanos = mFrameData.mFrameTimeNanos; synchronized (mLock) { final long now = System.nanoTime(); callbacks = mCallbackQueues[callbackType].extractDueCallbacksLocked( now / TimeUtils.NANOS_PER_MS); if (callbacks == null ) { return ; } mCallbacksRunning = true ; if (callbackType == Choreographer.CALLBACK_COMMIT) { final long jitterNanos = now - frameTimeNanos; if (frameIntervalNanos > 0 && jitterNanos >= 2 * frameIntervalNanos) { final long lastFrameOffset = jitterNanos % frameIntervalNanos + frameIntervalNanos; frameTimeNanos = now - lastFrameOffset; mLastFrameTimeNanos = frameTimeNanos; mFrameData.update(frameTimeNanos, mDisplayEventReceiver, jitterNanos); } } } try { Trace.traceBegin(Trace.TRACE_TAG_VIEW, CALLBACK_TRACE_TITLES[callbackType]); for (CallbackRecord c = callbacks; c != null ; c = c.next) { c.run(mFrameData); } } finally { synchronized (mLock) { mCallbacksRunning = false ; do { final CallbackRecord next = callbacks.next; recycleCallbackLocked(callbacks); callbacks = next; } while (callbacks != null ); } Trace.traceEnd(Trace.TRACE_TAG_VIEW); } }
修正帧时间基准以应对严重掉帧 1 2 3 4 5 6 7 8 9 if (callbackType == Choreographer.CALLBACK_COMMIT) { final long jitterNanos = now - frameTimeNanos; if (frameIntervalNanos > 0 && jitterNanos >= 2 * frameIntervalNanos) { final long lastFrameOffset = jitterNanos % frameIntervalNanos + frameIntervalNanos; frameTimeNanos = now - lastFrameOffset; mLastFrameTimeNanos = frameTimeNanos; mFrameData.update(frameTimeNanos, mDisplayEventReceiver, jitterNanos); } }
这在 Choreographer 的底层逻辑中是一个非常重要的保护机制,用于解决因严重的掉帧或主线程卡顿导致的 “逻辑时间偏差” 。
核心意图:为什么要进行这一步计算? 在 Android 的动画(Animation)和图形渲染中,所有计算都是基于 frameTimeNanos 这个基准的。计算逻辑通常如下:
progress = (currentTime - startTime) / duration
如果系统发生了严重的卡顿(例如主线程阻塞了 500ms),frameTimeNanos 依然停留在 500ms 之前。如果不进行校正,当代码恢复执行时,程序会使用这个“过时”的 frameTimeNanos。这会导致:
动画“跳变” :动画会瞬间计算出很大的 delta,导致元素直接从起点“瞬移”到终点,产生视觉上的闪烁。物理引擎异常 :如果你的代码里有基于物理模拟的逻辑,巨大的时间差会导致计算出的速度、位移爆炸。
代码逻辑拆解 这段代码在 CALLBACK_COMMIT 阶段触发,其逻辑是在检测到极度严重掉帧 时,强行将“当前的逻辑帧时间”重置到最近的一个有效时间点。
**jitterNanos (抖动/延迟量)**:
1 jitterNanos = now - frameTimeNanos
这是当前物理时间(now)距离该帧预期执行时间(frameTimeNanos)的偏移量。如果该值很大,说明我们在这一帧上滞后了很多。
**阈值判断 (jitterNanos >= 2 \* frameIntervalNanos)**:
这是为了避免误判。只有当延迟超过 2 个帧周期(在 60Hz 下约 > 33.3ms)时,才会介入。这说明系统已经错过了至少一个 VSYNC 信号,进入了严重的掉帧状态。
**重新对齐 frameTimeNanos**:
1 2 final long lastFrameOffset = jitterNanos % frameIntervalNanos + frameIntervalNanos;frameTimeNanos = now - lastFrameOffset;
这里将 frameTimeNanos 设置为 now 减去一个偏移量。这个偏移量被强制限制在 frameIntervalNanos 到 2 * frameIntervalNanos 之间。
效果 :它将 frameTimeNanos “强制拉回”到距离当前 now 最近的、符合渲染周期节奏的时间点。
可视化理解 上图展示了当发生卡顿时,虚拟时间轴如何被校准以平滑后续动画。
状态 逻辑时间点 结果
正常情况 frameTimeNanos 是旧的信号时间动画平滑,delta 很小。
严重卡顿 frameTimeNanos 滞后 > 33ms如果不修正,动画下一帧会因为 currentTime - frameTimeNanos 过大而发生“ teleport” (瞬移)。
修正后 frameTimeNanos 被重置到 now - interval动画认为上一帧是 16.6ms 前,从而继续平滑过渡,掩盖了卡顿期间的时间断层。
与 View 相关的耗时统计 核心分类逻辑:通过 callbackType 实现“打标签” Choreographer 内部维护了一个数组:
1 2 3 4 5 6 7 private static final String[] CALLBACK_TRACE_TITLES = { "input" , "animation" , "insets_animation" , "traversal" , "commit" };
当 doCallbacks(int callbackType, ...) 被调用时,代码执行的是: Trace.traceBegin(Trace.TRACE_TAG_VIEW, CALLBACK_TRACE_TITLES[callbackType]);
对于 Input :传入 callbackType = 0,字符串就是 "input"。对于 Animation :传入 callbackType = 1,字符串就是 "animation"。
核心对应关系表
CALLBACK_TRACE_TITLES (Trace 标签) FrameMetrics 对应指标 (Duration) 核心职能
“input” INPUT_HANDLING_DURATION处理 MotionEvent、按键事件等。
“animation” ANIMATION_DURATION处理 ValueAnimator 等动画逻辑。
“insets_animation” INSETS_ANIMATION_DURATION处理窗口插屏(如键盘弹出)动画。
“traversal” LAYOUT_MEASURE_DURATION执行 performTraversals,即 Measure + Layout。
“commit” SYNC_DURATION同步 RenderNode 数据到渲染线程 (RenderThread)。
核心负载:Choreographer.FrameData 封装了 VSYNC 信号的时间戳和多组呈现时间线(Frame Timeline),这是现代 Android 系统平滑显示的核心数据结构。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 public static class FrameData { private long mFrameTimeNanos; private FrameTimeline[] mFrameTimelines; private int mPreferredFrameTimelineIndex; private boolean mInCallback = false ; FrameData() { allocateFrameTimelines(DisplayEventReceiver.VsyncEventData.FRAME_TIMELINES_CAPACITY); } public long getFrameTimeNanos () { checkInCallback(); return mFrameTimeNanos; } @NonNull @SuppressLint("ArrayReturn") public FrameTimeline[] getFrameTimelines() { checkInCallback(); return mFrameTimelines; } @NonNull public FrameTimeline getPreferredFrameTimeline () { checkInCallback(); return mFrameTimelines[mPreferredFrameTimelineIndex]; } void setInCallback (boolean inCallback) { mInCallback = inCallback; for (int i = 0 ; i < mFrameTimelines.length; i++) { mFrameTimelines[i].setInCallback(inCallback); } } private void checkInCallback () { if (!mInCallback) { throw new IllegalStateException ( "FrameData 在 vsync 回调之外无效" ); } } private void allocateFrameTimelines (int length) { length = Math.max(1 , length); if (mFrameTimelines == null || mFrameTimelines.length != length) { mFrameTimelines = new FrameTimeline [length]; for (int i = 0 ; i < mFrameTimelines.length; i++) { mFrameTimelines[i] = new FrameTimeline (); } } } FrameTimeline update ( long frameTimeNanos, DisplayEventReceiver.VsyncEventData vsyncEventData) { allocateFrameTimelines(vsyncEventData.frameTimelinesLength); mFrameTimeNanos = frameTimeNanos; mPreferredFrameTimelineIndex = vsyncEventData.preferredFrameTimelineIndex; for (int i = 0 ; i < mFrameTimelines.length; i++) { DisplayEventReceiver.VsyncEventData.FrameTimeline frameTimeline = vsyncEventData.frameTimelines[i]; mFrameTimelines[i].update(frameTimeline.vsyncId, frameTimeline.expectedPresentationTime, frameTimeline.deadline); } return mFrameTimelines[mPreferredFrameTimelineIndex]; } FrameTimeline update ( long frameTimeNanos, DisplayEventReceiver displayEventReceiver, long jitterNanos) { int newPreferredIndex = 0 ; final long minimumDeadline = mFrameTimelines[mPreferredFrameTimelineIndex].mDeadlineNanos + jitterNanos; while (newPreferredIndex < mFrameTimelines.length - 1 && mFrameTimelines[newPreferredIndex].mDeadlineNanos < minimumDeadline) { newPreferredIndex++; } long newPreferredDeadline = mFrameTimelines[newPreferredIndex].mDeadlineNanos; if (newPreferredDeadline < minimumDeadline) { DisplayEventReceiver.VsyncEventData latestVsyncEventData = displayEventReceiver.getLatestVsyncEventData(); if (latestVsyncEventData == null ) { Log.w(TAG, "无法获取最新的 VsyncEventData。SurfaceFlinger 是否崩溃了?" ); } else { update(frameTimeNanos, latestVsyncEventData); } } else { update(frameTimeNanos, newPreferredIndex); } return mFrameTimelines[mPreferredFrameTimelineIndex]; } void update (long frameTimeNanos, int newPreferredFrameTimelineIndex) { mFrameTimeNanos = frameTimeNanos; mPreferredFrameTimelineIndex = newPreferredFrameTimelineIndex; } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 318 319 320 321 322 323 324 325 326 327 328 329 330 331 332 333 334 335 336 337 338 339 340 341 342 343 344 345 346 347 348 349 350 351 352 353 354 355 356 357 358 359 360 361 362 363 364 365 366 367 368 369 370 371 372 373 374 375 376 377 378 379 380 381 382 383 384 385 386 387 388 389 390 391 392 393 394 395 396 397 398 399 400 401 402 403 404 405 406 407 408 409 410 411 412 413 414 415 416 417 418 419 420 421 422 423 424 425 426 427 428 429 430 431 432 433 434 435 436 437 438 439 440 441 442 443 444 445 446 447 448 449 450 451 452 453 454 455 456 457 458 459 460 461 462 463 464 465 466 467 468 469 470 471 472 473 474 475 476 477 478 479 480 481 482 483 484 485 486 487 488 489 490 491 492 493 494 495 496 497 498 499 500 501 502 503 504 505 506 507 508 509 510 511 512 513 514 515 516 517 518 519 520 521 522 523 524 525 526 527 528 529 530 531 532 533 534 535 536 537 538 539 540 541 542 543 544 545 546 547 548 549 550 551 552 553 554 555 556 557 558 559 560 561 562 563 564 565 566 567 568 569 570 571 572 573 574 575 576 577 578 579 580 581 582 583 584 585 586 587 588 589 590 591 592 593 594 595 596 597 598 599 600 601 602 603 604 605 606 607 608 609 610 611 612 613 614 615 616 617 618 619 620 621 622 623 624 625 626 627 628 629 630 631 632 633 634 635 636 637 638 639 640 641 642 643 644 645 646 647 648 649 650 651 652 653 654 655 656 657 658 659 660 661 662 663 664 665 666 667 668 669 670 671 672 673 674 675 676 677 678 679 680 private void performTraversals () { final View host = mView; if (DBG) { System.out.println("======================================" ); System.out.println("performTraversals" ); host.debug(); } if (host == null || !mAdded) { mLastPerformTraversalsSkipDrawReason = host == null ? "no_host" : "not_added" ; return ; } if (mNumPausedForSync > 0 ) { if (Trace.isTagEnabled(Trace.TRACE_TAG_VIEW)) { Trace.instant(Trace.TRACE_TAG_VIEW, TextUtils.formatSimple("performTraversals#mNumPausedForSync=%d" , mNumPausedForSync)); } if (DEBUG_BLAST) { Log.d(mTag, "Skipping traversal due to sync " + mNumPausedForSync); } mLastPerformTraversalsSkipDrawReason = "paused_for_sync" ; return ; } mIsInTraversal = true ; mWillDrawSoon = true ; boolean cancelDraw = false ; String cancelReason = null ; boolean isSyncRequest = false ; boolean windowSizeMayChange = false ; WindowManager.LayoutParams lp = mWindowAttributes; int desiredWindowWidth; int desiredWindowHeight; final int viewVisibility = getHostVisibility(); final String viewVisibilityReason = getHostVisibilityReason(); final boolean viewVisibilityChanged = !mFirst && (mViewVisibility != viewVisibility || mNewSurfaceNeeded || mAppVisibilityChanged); mAppVisibilityChanged = false ; final boolean viewUserVisibilityChanged = !mFirst && ((mViewVisibility == View.VISIBLE) != (viewVisibility == View.VISIBLE)); final boolean shouldOptimizeMeasure = shouldOptimizeMeasure(lp); WindowManager.LayoutParams params = null ; Rect frame = mWinFrame; if (mFirst) { mFullRedrawNeeded = true ; mLayoutRequested = true ; final Configuration config = getConfiguration(); if (shouldUseDisplaySize(lp)) { Point size = new Point (); mDisplay.getRealSize(size); desiredWindowWidth = size.x; desiredWindowHeight = size.y; } else if (lp.width == ViewGroup.LayoutParams.WRAP_CONTENT || lp.height == ViewGroup.LayoutParams.WRAP_CONTENT) { final Rect bounds = getWindowBoundsInsetSystemBars(); desiredWindowWidth = bounds.width(); desiredWindowHeight = bounds.height(); } else { desiredWindowWidth = frame.width(); desiredWindowHeight = frame.height(); } mAttachInfo.mUse32BitDrawingCache = true ; mAttachInfo.mWindowVisibility = viewVisibility; mAttachInfo.mRecomputeGlobalAttributes = false ; mLastConfigurationFromResources.setTo(config); mLastSystemUiVisibility = mAttachInfo.mSystemUiVisibility; if (mViewLayoutDirectionInitial == View.LAYOUT_DIRECTION_INHERIT) { host.setLayoutDirection(config.getLayoutDirection()); } host.dispatchAttachedToWindow(mAttachInfo, 0 ); mAttachInfo.mTreeObserver.dispatchOnWindowAttachedChange(true ); dispatchApplyInsets(host); if (!mOnBackInvokedDispatcher.isOnBackInvokedCallbackEnabled() && mWindowlessBackKeyCallback == null ) { registerCompatOnBackInvokedCallback(); } } else { desiredWindowWidth = frame.width(); desiredWindowHeight = frame.height(); if (desiredWindowWidth != mWidth || desiredWindowHeight != mHeight) { if (DEBUG_ORIENTATION) Log.v(mTag, "View " + host + " resized to: " + frame); mFullRedrawNeeded = true ; mLayoutRequested = true ; windowSizeMayChange = true ; } } if (viewVisibilityChanged) { mAttachInfo.mWindowVisibility = viewVisibility; host.dispatchWindowVisibilityChanged(viewVisibility); mAttachInfo.mTreeObserver.dispatchOnWindowVisibilityChange(viewVisibility); if (viewUserVisibilityChanged) { host.dispatchVisibilityAggregated(viewVisibility == View.VISIBLE); } if (viewVisibility != View.VISIBLE || mNewSurfaceNeeded) { endDragResizing(); destroyHardwareResources(); } if (shouldEnableDvrr() && viewVisibility == View.VISIBLE) { boostFrameRate(FRAME_RATE_BOOST_TIME); } } if (mAttachInfo.mWindowVisibility != View.VISIBLE) { host.clearAccessibilityFocus(); } getRunQueue().executeActions(mAttachInfo.mHandler); if (mFirst) { mAttachInfo.mInTouchMode = !mAddedTouchMode; ensureTouchModeLocally(mAddedTouchMode); } boolean layoutRequested = mLayoutRequested && (!mStopped || mReportNextDraw); if (layoutRequested) { if (!mFirst) { if (lp.width == ViewGroup.LayoutParams.WRAP_CONTENT || lp.height == ViewGroup.LayoutParams.WRAP_CONTENT) { windowSizeMayChange = true ; if (shouldUseDisplaySize(lp)) { Point size = new Point (); mDisplay.getRealSize(size); desiredWindowWidth = size.x; desiredWindowHeight = size.y; } else { final Rect bounds = getWindowBoundsInsetSystemBars(); desiredWindowWidth = bounds.width(); desiredWindowHeight = bounds.height(); } } } windowSizeMayChange |= measureHierarchy(host, lp, mView.getContext().getResources(), desiredWindowWidth, desiredWindowHeight, shouldOptimizeMeasure); } if (collectViewAttributes()) { params = lp; } if (mAttachInfo.mForceReportNewAttributes) { mAttachInfo.mForceReportNewAttributes = false ; params = lp; } if (mFirst || mAttachInfo.mViewVisibilityChanged) { mAttachInfo.mViewVisibilityChanged = false ; int resizeMode = mSoftInputMode & SOFT_INPUT_MASK_ADJUST; if (resizeMode == WindowManager.LayoutParams.SOFT_INPUT_ADJUST_UNSPECIFIED) { final int N = mAttachInfo.mScrollContainers.size(); for (int i=0 ; i<N; i++) { if (mAttachInfo.mScrollContainers.get(i).isShown()) { resizeMode = WindowManager.LayoutParams.SOFT_INPUT_ADJUST_RESIZE; } } if (resizeMode == 0 ) { resizeMode = WindowManager.LayoutParams.SOFT_INPUT_ADJUST_PAN; } if ((lp.softInputMode & SOFT_INPUT_MASK_ADJUST) != resizeMode) { lp.softInputMode = (lp.softInputMode & ~SOFT_INPUT_MASK_ADJUST) | resizeMode; params = lp; } } } if (mApplyInsetsRequested) { dispatchApplyInsets(host); if (mLayoutRequested) { windowSizeMayChange |= measureHierarchy(host, lp, mView.getContext().getResources(), desiredWindowWidth, desiredWindowHeight, shouldOptimizeMeasure); } } if (layoutRequested) { mLayoutRequested = false ; } boolean windowShouldResize = layoutRequested && windowSizeMayChange && ((mWidth != host.getMeasuredWidth() || mHeight != host.getMeasuredHeight()) || (lp.width == ViewGroup.LayoutParams.WRAP_CONTENT && frame.width() < desiredWindowWidth && frame.width() != mWidth) || (lp.height == ViewGroup.LayoutParams.WRAP_CONTENT && frame.height() < desiredWindowHeight && frame.height() != mHeight)); windowShouldResize |= mDragResizing && mPendingDragResizing; final boolean computesInternalInsets = mAttachInfo.mTreeObserver.hasComputeInternalInsetsListeners() || mAttachInfo.mHasNonEmptyGivenInternalInsets; boolean insetsPending = false ; int relayoutResult = 0 ; boolean updatedConfiguration = false ; final int surfaceGenerationId = mSurface.getGenerationId(); final boolean isViewVisible = viewVisibility == View.VISIBLE; boolean surfaceSizeChanged = false ; boolean surfaceCreated = false ; boolean surfaceDestroyed = false ; boolean surfaceReplaced = false ; final boolean windowAttributesChanged = mWindowAttributesChanged; if (windowAttributesChanged) { mWindowAttributesChanged = false ; params = lp; } if (params != null ) { if ((host.mPrivateFlags & View.PFLAG_REQUEST_TRANSPARENT_REGIONS) != 0 && !PixelFormat.formatHasAlpha(params.format)) { params.format = PixelFormat.TRANSLUCENT; } adjustLayoutParamsForCompatibility(params, mInsetsController.getAppearanceControlled(), mInsetsController.isBehaviorControlled()); controlInsetsForCompatibility(params); if (mDispatchedSystemBarAppearance != params.insetsFlags.appearance) { mDispatchedSystemBarAppearance = params.insetsFlags.appearance; mView.onSystemBarAppearanceChanged(mDispatchedSystemBarAppearance); } } if (mFirst || windowShouldResize || viewVisibilityChanged || params != null || mForceNextWindowRelayout) { if (Trace.isTagEnabled(Trace.TRACE_TAG_VIEW)) { Trace.traceBegin(Trace.TRACE_TAG_VIEW, TextUtils.formatSimple("%s-relayoutWindow#" + "first=%b/resize=%b/vis=%b/params=%b/force=%b" , mTag, mFirst, windowShouldResize, viewVisibilityChanged, params != null , mForceNextWindowRelayout)); } mForceNextWindowRelayout = false ; insetsPending = computesInternalInsets && mWindowAttributes.providedInsets == null ; if (mSurfaceHolder != null ) { mSurfaceHolder.mSurfaceLock.lock(); mDrawingAllowed = true ; } boolean hwInitialized = false ; boolean dispatchApplyInsets = false ; boolean hadSurface = mSurface.isValid(); try { if (DEBUG_LAYOUT) { Log.i(mTag, "host=w:" + host.getMeasuredWidth() + ", h:" + host.getMeasuredHeight() + ", params=" + params); } if (mFirst || viewVisibilityChanged) { mViewFrameInfo.flags |= FrameInfo.FLAG_WINDOW_VISIBILITY_CHANGED; } relayoutResult = relayoutWindow(params, viewVisibility, insetsPending); cancelDraw = (relayoutResult & RELAYOUT_RES_CANCEL_AND_REDRAW) == RELAYOUT_RES_CANCEL_AND_REDRAW; cancelReason = "relayout" ; final boolean dragResizing = mPendingDragResizing; if (mSyncSeqId > mLastSyncSeqId) { mLastSyncSeqId = mSyncSeqId; if (DEBUG_BLAST) { Log.d(mTag, "Relayout called with blastSync" ); } reportNextDraw("relayout" ); mSyncBuffer = true ; isSyncRequest = true ; if (!cancelDraw) { mDrewOnceForSync = false ; } } final boolean surfaceControlChanged = (relayoutResult & RELAYOUT_RES_SURFACE_CHANGED) == RELAYOUT_RES_SURFACE_CHANGED; if (mSurfaceControl.isValid()) { updateOpacity(mWindowAttributes, dragResizing, surfaceControlChanged ); } } catch (RemoteException e) { } finally { if (Trace.isTagEnabled(Trace.TRACE_TAG_VIEW)) { Trace.traceEnd(Trace.TRACE_TAG_VIEW); } } if (DEBUG_ORIENTATION) Log.v( TAG, "Relayout returned: frame=" + frame + ", surface=" + mSurface); mAttachInfo.mWindowLeft = frame.left; mAttachInfo.mWindowTop = frame.top; if (mWidth != frame.width() || mHeight != frame.height()) { mWidth = frame.width(); mHeight = frame.height(); } if (mSurfaceHolder != null ) { if (mSurface.isValid()) { mSurfaceHolder.mSurface = mSurface; } mSurfaceHolder.setSurfaceFrameSize(mWidth, mHeight); mSurfaceHolder.mSurfaceLock.unlock(); if (surfaceCreated) { mSurfaceHolder.ungetCallbacks(); mIsCreating = true ; SurfaceHolder.Callback[] callbacks = mSurfaceHolder.getCallbacks(); if (callbacks != null ) { for (SurfaceHolder.Callback c : callbacks) { c.surfaceCreated(mSurfaceHolder); } } } if ((surfaceCreated || surfaceReplaced || surfaceSizeChanged || windowAttributesChanged) && mSurface.isValid()) { SurfaceHolder.Callback[] callbacks = mSurfaceHolder.getCallbacks(); if (callbacks != null ) { for (SurfaceHolder.Callback c : callbacks) { c.surfaceChanged(mSurfaceHolder, lp.format, mWidth, mHeight); } } mIsCreating = false ; } if (surfaceDestroyed) { notifyHolderSurfaceDestroyed(); mSurfaceHolder.mSurfaceLock.lock(); try { mSurfaceHolder.mSurface = new Surface (); } finally { mSurfaceHolder.mSurfaceLock.unlock(); } } } final ThreadedRenderer threadedRenderer = mAttachInfo.mThreadedRenderer; if (threadedRenderer != null && threadedRenderer.isEnabled()) { if (hwInitialized || mWidth != threadedRenderer.getWidth() || mHeight != threadedRenderer.getHeight() || mNeedsRendererSetup) { threadedRenderer.setup(mWidth, mHeight, mAttachInfo, mWindowAttributes.surfaceInsets); mNeedsRendererSetup = false ; } } if (!mStopped || mReportNextDraw) { if (mWidth != host.getMeasuredWidth() || mHeight != host.getMeasuredHeight() || dispatchApplyInsets || updatedConfiguration) { int childWidthMeasureSpec = getRootMeasureSpec(mWidth, lp.width, lp.privateFlags); int childHeightMeasureSpec = getRootMeasureSpec(mHeight, lp.height, lp.privateFlags); if (DEBUG_LAYOUT) Log.v(mTag, "糟糕,出了一些变化! mWidth=" + mWidth + " measuredWidth=" + host.getMeasuredWidth() + " mHeight=" + mHeight + " measuredHeight=" + host.getMeasuredHeight() + " dispatchApplyInsets=" + dispatchApplyInsets); performMeasure(childWidthMeasureSpec, childHeightMeasureSpec); int width = host.getMeasuredWidth(); int height = host.getMeasuredHeight(); boolean measureAgain = false ; if (lp.horizontalWeight > 0.0f ) { width += (int ) ((mWidth - width) * lp.horizontalWeight); childWidthMeasureSpec = MeasureSpec.makeMeasureSpec(width, MeasureSpec.EXACTLY); measureAgain = true ; } if (lp.verticalWeight > 0.0f ) { height += (int ) ((mHeight - height) * lp.verticalWeight); childHeightMeasureSpec = MeasureSpec.makeMeasureSpec(height, MeasureSpec.EXACTLY); measureAgain = true ; } if (measureAgain) { if (DEBUG_LAYOUT) Log.v(mTag, "嘿,让我们再测量一次:width=" + width + " height=" + height); performMeasure(childWidthMeasureSpec, childHeightMeasureSpec); } layoutRequested = true ; } } } else { maybeHandleWindowMove(frame); } if (mViewMeasureDeferred) { performMeasure( MeasureSpec.makeMeasureSpec(frame.width(), MeasureSpec.EXACTLY), MeasureSpec.makeMeasureSpec(frame.height(), MeasureSpec.EXACTLY)); } final boolean didLayout = layoutRequested && (!mStopped || mReportNextDraw); if (didLayout) { performLayout(lp, mWidth, mHeight); } if (mFirst) { if (sAlwaysAssignFocus || !isInTouchMode()) { if (DEBUG_INPUT_RESIZE) { Log.v(mTag, "First: mView.hasFocus()=" + mView.hasFocus()); } if (mView != null ) { if (!mView.hasFocus()) { mView.restoreDefaultFocus(); if (DEBUG_INPUT_RESIZE) { Log.v(mTag, "First: requested focused view=" + mView.findFocus()); } } else { if (DEBUG_INPUT_RESIZE) { Log.v(mTag, "First: existing focused view=" + mView.findFocus()); } } } } else { View focused = mView.findFocus(); if (focused instanceof ViewGroup && ((ViewGroup) focused).getDescendantFocusability() == ViewGroup.FOCUS_AFTER_DESCENDANTS) { focused.restoreDefaultFocus(); } } if (shouldEnableDvrr()) { boostFrameRate(FRAME_RATE_BOOST_TIME); } } final boolean changedVisibility = (viewVisibilityChanged || mFirst) && isViewVisible; if (changedVisibility) { maybeFireAccessibilityWindowStateChangedEvent(); } mFirst = false ; mWillDrawSoon = false ; mNewSurfaceNeeded = false ; mViewVisibility = viewVisibility; final boolean hasWindowFocus = mAttachInfo.mHasWindowFocus && isViewVisible; mImeFocusController.onTraversal(hasWindowFocus, mWindowAttributes); if ((relayoutResult & WindowManagerGlobal.RELAYOUT_RES_FIRST_TIME) != 0 ) { reportNextDraw("first_relayout" ); } mCheckIfCanDraw = isSyncRequest || cancelDraw; boolean cancelDueToPreDrawListener = mAttachInfo.mTreeObserver.dispatchOnPreDraw(); boolean cancelAndRedraw = cancelDueToPreDrawListener || (cancelDraw && mDrewOnceForSync); if (!cancelAndRedraw) { if (mActiveSurfaceSyncGroup != null ) { mSyncBuffer = true ; } createSyncIfNeeded(); notifyDrawStarted(isInWMSRequestedSync()); mDrewOnceForSync = true ; if (mActiveSurfaceSyncGroup != null && mSyncBuffer) { updateSyncInProgressCount(mActiveSurfaceSyncGroup); safeguardOverlappingSyncs(mActiveSurfaceSyncGroup); } } if (!isViewVisible) { if (mLastTraversalWasVisible) { logAndTrace("Not drawing due to not visible. Reason=" + viewVisibilityReason); } mLastPerformTraversalsSkipDrawReason = "view_not_visible" ; if (mPendingTransitions != null && mPendingTransitions.size() > 0 ) { for (int i = 0 ; i < mPendingTransitions.size(); ++i) { mPendingTransitions.get(i).endChangingAnimations(); } mPendingTransitions.clear(); } handleSyncRequestWhenNoAsyncDraw(mActiveSurfaceSyncGroup, mHasPendingTransactions, mPendingTransaction, "view not visible" ); } else if (cancelAndRedraw) { if (!mWasLastDrawCanceled) { logAndTrace("Canceling draw." + " cancelDueToPreDrawListener=" + cancelDueToPreDrawListener + " cancelDueToSync=" + (cancelDraw && mDrewOnceForSync)); } mLastPerformTraversalsSkipDrawReason = cancelDueToPreDrawListener ? "predraw_" + mAttachInfo.mTreeObserver.getLastDispatchOnPreDrawCanceledReason() : "cancel_" + cancelReason; scheduleTraversals(); } else { if (mWasLastDrawCanceled) { logAndTrace("Draw frame after cancel" ); } if (!mLastTraversalWasVisible) { logAndTrace("Start draw after previous draw not visible" ); } if (mPendingTransitions != null && mPendingTransitions.size() > 0 ) { for (int i = 0 ; i < mPendingTransitions.size(); ++i) { mPendingTransitions.get(i).startChangingAnimations(); } mPendingTransitions.clear(); } if (!performDraw(mActiveSurfaceSyncGroup)) { handleSyncRequestWhenNoAsyncDraw(mActiveSurfaceSyncGroup, mHasPendingTransactions, mPendingTransaction, mLastPerformDrawSkippedReason); } } mWasLastDrawCanceled = cancelAndRedraw; mLastTraversalWasVisible = isViewVisible; if (mAttachInfo.mContentCaptureEvents != null ) { notifyContentCaptureEvents(); } mIsInTraversal = false ; mRelayoutRequested = false ; if (!cancelAndRedraw) { mReportNextDraw = false ; mLastReportNextDrawReason = null ; mActiveSurfaceSyncGroup = null ; if (mHasPendingTransactions) { mPendingTransaction.apply(); mHasPendingTransactions = false ; } mSyncBuffer = false ; if (isInWMSRequestedSync()) { mWmsRequestSyncGroup.markSyncReady(); mWmsRequestSyncGroup = null ; mWmsRequestSyncGroupState = WMS_SYNC_NONE; } } if (mDrawnThisFrame) { mDrawnThisFrame = false ; if (!mInvalidationIdleMessagePosted && sSurfaceFlingerBugfixFlagValue) { mInvalidationIdleMessagePosted = true ; mHandler.sendEmptyMessageDelayed(MSG_CHECK_INVALIDATION_IDLE, IDLE_TIME_MILLIS); } setCategoryFromCategoryCounts(); updateInfrequentCount(); updateFrameRateFromThreadedRendererViews(); setPreferredFrameRate(mPreferredFrameRate); setPreferredFrameRateCategory(mPreferredFrameRateCategory); if (mPreferredFrameRate > 0 || (mLastPreferredFrameRate != 0 && mPreferredFrameRate == 0 ) ) { mHandler.removeMessages(MSG_FRAME_RATE_SETTING); mHandler.sendEmptyMessageDelayed(MSG_FRAME_RATE_SETTING, FRAME_RATE_SETTING_REEVALUATE_TIME); } mFrameRateCategoryHighCount = mFrameRateCategoryHighCount > 0 ? mFrameRateCategoryHighCount - 1 : mFrameRateCategoryHighCount; mFrameRateCategoryNormalCount = mFrameRateCategoryNormalCount > 0 ? mFrameRateCategoryNormalCount - 1 : mFrameRateCategoryNormalCount; mFrameRateCategoryLowCount = mFrameRateCategoryLowCount > 0 ? mFrameRateCategoryLowCount - 1 : mFrameRateCategoryLowCount; mPreferredFrameRateCategory = FRAME_RATE_CATEGORY_DEFAULT; mPreferredFrameRate = -1 ; mIsFrameRateConflicted = false ; mFrameRateCategoryChangeReason = FRAME_RATE_CATEGORY_REASON_UNKNOWN; } else if (mPreferredFrameRate == 0 ) { setPreferredFrameRate(0 ); mPreferredFrameRate = -1 ; } }
指令录制:ThreadedRenderer.draw() 将 UI 线程的 Java 代码绘制逻辑录制为 Native 层的 DisplayList。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 void draw (View view, AttachInfo attachInfo, DrawCallbacks callbacks) { attachInfo.mViewRootImpl.mViewFrameInfo.markDrawStart(); updateRootDisplayList(view, callbacks); if (attachInfo.mPendingAnimatingRenderNodes != null ) { final int count = attachInfo.mPendingAnimatingRenderNodes.size(); for (int i = 0 ; i < count; i++) { registerAnimatingRenderNode( attachInfo.mPendingAnimatingRenderNodes.get(i)); } attachInfo.mPendingAnimatingRenderNodes.clear(); attachInfo.mPendingAnimatingRenderNodes = null ; } final FrameInfo frameInfo = attachInfo.mViewRootImpl.getUpdatedFrameInfo(); int syncResult = syncAndDrawFrame(frameInfo); if ((syncResult & SYNC_LOST_SURFACE_REWARD_IF_FOUND) != 0 ) { Log.w("HWUI" , "Surface 丢失,强制进行重新布局 (relayout)" ); attachInfo.mViewRootImpl.mForceNextWindowRelayout = true ; attachInfo.mViewRootImpl.requestLayout(); } if ((syncResult & SYNC_REDRAW_REQUESTED) != 0 ) { attachInfo.mViewRootImpl.invalidate(); } }
Native 层:RenderThread 异步渲染 (frameworks/base/libs/hwui/) 资源同步:CanvasContext::prepareTree() 在正式绘制前,将 UI 线程录制的变化应用到 Native 渲染树中。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 void CanvasContext::prepareTree (TreeInfo& info, int64_t * uiFrameInfo, int64_t syncQueued, RenderNode* target) mRenderThread.removeFrameCallback (this ); const auto reason = wasSkipped (mCurrentFrameInfo); if (reason.has_value ()) { if (!mSkippedFrameInfo) { switch (*reason) { case SkippedFrameReason::AlreadyDrawn: case SkippedFrameReason::NoBuffer: case SkippedFrameReason::NoOutputTarget: mSkippedFrameInfo.emplace (); mSkippedFrameInfo->vsyncId = mCurrentFrameInfo->get (FrameInfoIndex::FrameTimelineVsyncId); mSkippedFrameInfo->startTime = mCurrentFrameInfo->get (FrameInfoIndex::FrameStartTime); break ; case SkippedFrameReason::DrawingOff: case SkippedFrameReason::ContextIsStopped: case SkippedFrameReason::NothingToDraw: break ; } } } else { mCurrentFrameInfo = mJankTracker.startFrame (); mSkippedFrameInfo.reset (); } mCurrentFrameInfo->importUiThreadInfo (uiFrameInfo); mCurrentFrameInfo->set (FrameInfoIndex::SyncQueued) = syncQueued; mCurrentFrameInfo->markSyncStart (); info.damageAccumulator = &mDamageAccumulator; info.layerUpdateQueue = &mLayerUpdateQueue; info.damageGenerationId = mDamageId++; info.out.skippedFrameReason = std::nullopt ; mAnimationContext->startFrame (info.mode); for (const sp<RenderNode>& node : mRenderNodes) { info.mode = (node.get () == target ? TreeInfo::MODE_FULL : TreeInfo::MODE_RT_ONLY); node->prepareTree (info); GL_CHECKPOINT (MODERATE); } mAnimationContext->runRemainingAnimations (info); GL_CHECKPOINT (MODERATE); freePrefetchedLayers (); GL_CHECKPOINT (MODERATE); mIsDirty = true ; if (CC_UNLIKELY (!hasOutputTarget ())) { info.out.skippedFrameReason = SkippedFrameReason::NoOutputTarget; mCurrentFrameInfo->setSkippedFrameReason (*info.out.skippedFrameReason); return ; } if (CC_LIKELY (mSwapHistory.size () && !info.forceDrawFrame)) { nsecs_t latestVsync = mRenderThread.timeLord ().latestVsync (); SwapHistory& lastSwap = mSwapHistory.back (); nsecs_t vsyncDelta = std::abs (lastSwap.vsyncTime - latestVsync); if (vsyncDelta < 2 _ms) { info.out.skippedFrameReason = SkippedFrameReason::AlreadyDrawn; } } else { info.out.skippedFrameReason = std::nullopt ; } if (mRenderNodes.size () > 2 && !mRenderNodes[1 ]->isRenderable ()) { info.out.skippedFrameReason = SkippedFrameReason::NothingToDraw; } if (!info.out.skippedFrameReason) { int err = mNativeSurface->reserveNext (); if (err != OK) { info.out.skippedFrameReason = SkippedFrameReason::NoBuffer; mCurrentFrameInfo->setSkippedFrameReason (*info.out.skippedFrameReason); ALOGW ("reserveNext 失败,错误 = %d (%s)" , err, strerror (-err)); if (err != TIMED_OUT) { setSurface (nullptr ); return ; } } } else { mCurrentFrameInfo->setSkippedFrameReason (*info.out.skippedFrameReason); } bool postedFrameCallback = false ; if (info.out.hasAnimations || info.out.skippedFrameReason) { if (CC_UNLIKELY (!Properties::enableRTAnimations)) { info.out.requiresUiRedraw = true ; } if (!info.out.requiresUiRedraw) { mRenderThread.postFrameCallback (this ); postedFrameCallback = true ; } } if (!postedFrameCallback && info.out.animatedImageDelay != TreeInfo::Out::kNoAnimatedImageDelay) { const nsecs_t kFrameTime = mRenderThread.timeLord ().frameIntervalNanos (); if (info.out.animatedImageDelay <= kFrameTime) { mRenderThread.postFrameCallback (this ); } else { const auto delay = info.out.animatedImageDelay - kFrameTime; int genId = mGenerationID; mRenderThread.queue ().postDelayed (delay, [this , genId]() { if (mGenerationID == genId) { mRenderThread.postFrameCallback (this ); } }); } } }
绘制与提交:CanvasContext::draw() 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 void CanvasContext::draw (bool solelyTextureViewUpdates) #ifdef __ANDROID__ if (auto grContext = getGrContext ()) { if (grContext->abandoned ()) { if (grContext->isDeviceLost ()) { LOG_ALWAYS_FATAL ("意外丢失 GPU 设备" ); return ; } LOG_ALWAYS_FATAL ("在 CanvasContext::draw 开始时 GrContext 已被放弃" ); return ; } } #endif SkRect dirty; mDamageAccumulator.finish (&dirty); nsecs_t syncDelayDuration = mSyncDelayDuration; nsecs_t idleDuration = mIdleDuration; mSyncDelayDuration = 0 ; mIdleDuration = 0 ; const auto skippedFrameReason = [&]() -> std::optional<SkippedFrameReason> { if (!Properties::isDrawingEnabled ()) { return SkippedFrameReason::DrawingOff; } if (dirty.isEmpty () && Properties::skipEmptyFrames && !surfaceRequiresRedraw ()) { return SkippedFrameReason::NothingToDraw; } return std::nullopt ; }(); if (skippedFrameReason) { mCurrentFrameInfo->setSkippedFrameReason (*skippedFrameReason); #ifdef __ANDROID__ if (auto grContext = getGrContext ()) { grContext->flushAndSubmit (); } #endif waitOnFences (); for (auto & func : mFrameCommitCallbacks) { std::invoke (func, false ); } mFrameCommitCallbacks.clear (); return ; } ScopedActiveContext activeContext (this ) ; mCurrentFrameInfo->set (FrameInfoIndex::FrameInterval) = mRenderThread.timeLord ().frameIntervalNanos (); mCurrentFrameInfo->markIssueDrawCommandsStart (); Frame frame = getFrame (); SkRect windowDirty = computeDirtyRect (frame, &dirty); ATRACE_FORMAT ("Drawing " RECT_STRING, SK_RECT_ARGS (dirty)); IRenderPipeline::DrawResult drawResult; { drawResult = mRenderPipeline->draw ( frame, windowDirty, dirty, mLightGeometry, &mLayerUpdateQueue, mContentDrawBounds, mOpaque, mLightInfo, mRenderNodes, &(profiler ()), mBufferParams, profilerLock ()); } uint64_t frameCompleteNr = getFrameNumber (); waitOnFences (); if (mNativeSurface) { const auto vsyncId = mCurrentFrameInfo->get (FrameInfoIndex::FrameTimelineVsyncId); if (vsyncId != UiFrameInfoBuilder::INVALID_VSYNC_ID) { const auto inputEventId = static_cast <int32_t >(mCurrentFrameInfo->get (FrameInfoIndex::InputEventId)); const ANativeWindowFrameTimelineInfo ftl = { .frameNumber = frameCompleteNr, .frameTimelineVsyncId = vsyncId, .inputEventId = inputEventId, .startTimeNanos = mCurrentFrameInfo->get (FrameInfoIndex::FrameStartTime), .useForRefreshRateSelection = solelyTextureViewUpdates, .skippedFrameVsyncId = mSkippedFrameInfo ? mSkippedFrameInfo->vsyncId : UiFrameInfoBuilder::INVALID_VSYNC_ID, .skippedFrameStartTimeNanos = mSkippedFrameInfo ? mSkippedFrameInfo->startTime : 0 , }; native_window_set_frame_timeline_info (mNativeSurface->getNativeWindow (), ftl); } } bool requireSwap = false ; bool didDraw = false ; int error = OK; bool didSwap = mRenderPipeline->swapBuffers (frame, drawResult, windowDirty, mCurrentFrameInfo, &requireSwap); mCurrentFrameInfo->set (FrameInfoIndex::CommandSubmissionCompleted) = std::max ( drawResult.commandSubmissionTime, mCurrentFrameInfo->get (FrameInfoIndex::SwapBuffers)); mIsDirty = false ; if (requireSwap) { didDraw = true ; error = mNativeSurface->getAndClearError (); if (error == TIMED_OUT) { mRenderThread.postFrameCallback (this ); didDraw = false ; } else if (error != OK || !didSwap) { setSurface (nullptr ); didDraw = false ; } SwapHistory& swap = mSwapHistory.next (); if (didDraw) { swap.damage = windowDirty; } else { float max = static_cast <float >(INT_MAX); swap.damage = SkRect::MakeWH (max, max); } swap.swapCompletedTime = systemTime (SYSTEM_TIME_MONOTONIC); swap.vsyncTime = mRenderThread.timeLord ().latestVsync (); if (didDraw) { nsecs_t dequeueStart = ANativeWindow_getLastDequeueStartTime (mNativeSurface->getNativeWindow ()); if (dequeueStart < mCurrentFrameInfo->get (FrameInfoIndex::SyncStart)) { swap.dequeueDuration = 0 ; } else { swap.dequeueDuration = ANativeWindow_getLastDequeueDuration (mNativeSurface->getNativeWindow ()); } swap.queueDuration = ANativeWindow_getLastQueueDuration (mNativeSurface->getNativeWindow ()); } else { swap.dequeueDuration = 0 ; swap.queueDuration = 0 ; } mCurrentFrameInfo->set (FrameInfoIndex::DequeueBufferDuration) = swap.dequeueDuration; mCurrentFrameInfo->set (FrameInfoIndex::QueueBufferDuration) = swap.queueDuration; mHaveNewSurface = false ; mFrameNumber = 0 ; } else { mCurrentFrameInfo->set (FrameInfoIndex::DequeueBufferDuration) = 0 ; mCurrentFrameInfo->set (FrameInfoIndex::QueueBufferDuration) = 0 ; } mCurrentFrameInfo->markSwapBuffersCompleted (); #if LOG_FRAMETIME_MMA float thisFrame = mCurrentFrameInfo->duration (FrameInfoIndex::IssueDrawCommandsStart, FrameInfoIndex::FrameCompleted) / NANOS_PER_MILLIS_F; if (sFrameCount) { sBenchMma = ((9 * sBenchMma) + thisFrame) / 10 ; } else { sBenchMma = thisFrame; } if (++sFrameCount == 10 ) { sFrameCount = 1 ; ALOGD ("平均帧耗时: %.4f" , sBenchMma); } #endif if (didSwap) { for (auto & func : mFrameCommitCallbacks) { std::invoke (func, true ); } mFrameCommitCallbacks.clear (); } if (requireSwap) { if (mExpectSurfaceStats) { reportMetricsWithPresentTime (); { std::lock_guard lock (mLast4FrameMetricsInfosMutex) ; FrameMetricsInfo& next = mLast4FrameMetricsInfos.next (); next.frameInfo = mCurrentFrameInfo; next.frameNumber = frameCompleteNr; next.surfaceId = mSurfaceControlGenerationId; } } else { mCurrentFrameInfo->markFrameCompleted (); mCurrentFrameInfo->set (FrameInfoIndex::GpuCompleted) = mCurrentFrameInfo->get (FrameInfoIndex::FrameCompleted); std::scoped_lock lock (mFrameInfoMutex) ; mJankTracker.finishFrame (*mCurrentFrameInfo, mFrameMetricsReporter, frameCompleteNr, mSurfaceControlGenerationId); } } int64_t intendedVsync = mCurrentFrameInfo->get (FrameInfoIndex::IntendedVsync); int64_t frameDeadline = mCurrentFrameInfo->get (FrameInfoIndex::FrameDeadline); int64_t dequeueBufferDuration = mCurrentFrameInfo->get (FrameInfoIndex::DequeueBufferDuration); mHintSessionWrapper->updateTargetWorkDuration (frameDeadline - intendedVsync); if (didDraw) { int64_t frameStartTime = mCurrentFrameInfo->get (FrameInfoIndex::FrameStartTime); int64_t frameDuration = systemTime (SYSTEM_TIME_MONOTONIC) - frameStartTime; int64_t actualDuration = frameDuration - (std::min (syncDelayDuration, mLastDequeueBufferDuration)) - dequeueBufferDuration - idleDuration; mHintSessionWrapper->reportActualWorkDuration (actualDuration); mHintSessionWrapper->setActiveFunctorThreads ( WebViewFunctorManager::instance ().getRenderingThreadsForActiveFunctors ()); } mLastDequeueBufferDuration = dequeueBufferDuration; mRenderThread.cacheManager ().onFrameCompleted (); return ; }
COMMAND_ISSUE_DURATION (指令发布)时间的计算 计时起点 在代码第 40 行,它通过一个名为 markIssueDrawCommandsStart() 的函数打入了一个时间戳:
1 2 mCurrentFrameInfo->markIssueDrawCommandsStart ();
计时终点 在代码第 104 行,记录了命令提交完成的时间:
1 2 mCurrentFrameInfo->set (FrameInfoIndex::CommandSubmissionCompleted) = std::max ( drawResult.commandSubmissionTime, mCurrentFrameInfo->get (FrameInfoIndex::SwapBuffers));
你可能会疑惑:为什么要取 drawResult.commandSubmissionTime 和 mCurrentFrameInfo->get(FrameInfoIndex::SwapBuffers) 的最大值?
这主要是为了防止 时间戳逻辑倒置 :
理想情况: 命令提交(Submission)应该发生在 SwapBuffers 之前。实际情况(驱动行为): 在某些图形驱动实现中,SwapBuffers(交换缓冲区)操作实际上包含了隐含的“命令刷新(Flush)”。也就是说,虽然 HWUI 认为提交在 SwapBuffers 之前就完成了,但实际上驱动程序可能在 SwapBuffers 调用时才真正完成了最后一块指令的推送。为什么用 max: 如果 drawResult.commandSubmissionTime(我们测量的提交完成时间)比 SwapBuffers 的时间还要早,这在统计上是没有问题的。但如果驱动程序的 SwapBuffers 动作比我们记录的提交时间还晚,为了保证性能数据的逻辑性(提交动作不可能在交换缓冲区之后才完成),系统强制将 CommandSubmissionCompleted 的时间点至少设为 SwapBuffers 的时间。
将渲染完成的 Buffer 提交给 SurfaceFlinger SkiaOpenGLPipeline
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 #include "pipeline/skia/SkiaOpenGLPipeline.h" #include <GrBackendSurface.h> #include <SkBlendMode.h> #include <SkImageInfo.h> #include <cutils/properties.h> #include <gui/TraceUtils.h> #include <include/gpu/ganesh/SkSurfaceGanesh.h> #include <include/gpu/ganesh/gl/GrGLBackendSurface.h> #include <include/gpu/gl/GrGLTypes.h> #include <strings.h> #include "DeferredLayerUpdater.h" #include "FrameInfo.h" #include "LightingInfo.h" #include "hwui/Bitmap.h" #include "pipeline/skia/LayerDrawable.h" #include "pipeline/skia/SkiaGpuPipeline.h" #include "pipeline/skia/SkiaProfileRenderer.h" #include "private/hwui/DrawGlInfo.h" #include "renderstate/RenderState.h" #include "renderthread/EglManager.h" #include "renderthread/Frame.h" #include "renderthread/IRenderPipeline.h" #include "utils/GLUtils.h" using namespace android::uirenderer::renderthread;namespace android {namespace uirenderer {namespace skiapipeline {SkiaOpenGLPipeline::SkiaOpenGLPipeline (RenderThread& thread) : SkiaGpuPipeline (thread), mEglManager (thread.eglManager ()) { thread.renderState ().registerContextCallback (this ); } SkiaOpenGLPipeline::~SkiaOpenGLPipeline () { mRenderThread.renderState ().removeContextCallback (this ); } MakeCurrentResult SkiaOpenGLPipeline::makeCurrent () { bool wasSurfaceless = mEglManager.isCurrent (EGL_NO_SURFACE); if (mHardwareBuffer) { mRenderThread.requireGlContext (); } else if (!isSurfaceReady () && mNativeWindow) { setSurface (mNativeWindow.get (), mSwapBehavior); } EGLint error = 0 ; if (!mEglManager.makeCurrent (mEglSurface, &error)) { return MakeCurrentResult::AlreadyCurrent; } EGLint majorVersion = 0 ; eglQueryContext (eglGetCurrentDisplay (), eglGetCurrentContext (), EGL_CONTEXT_CLIENT_VERSION, &majorVersion); if (error == 0 && (majorVersion > 2 ) && wasSurfaceless && mEglSurface != EGL_NO_SURFACE) { GLint curReadFB = 0 ; GLint curDrawFB = 0 ; glGetIntegerv (GL_READ_FRAMEBUFFER_BINDING, &curReadFB); glGetIntegerv (GL_DRAW_FRAMEBUFFER_BINDING, &curDrawFB); GLint buffer = GL_NONE; glBindFramebuffer (GL_FRAMEBUFFER, 0 ); glGetIntegerv (GL_DRAW_BUFFER0, &buffer); if (buffer == GL_NONE) { const GLenum drawBuffer = GL_BACK; glDrawBuffers (1 , &drawBuffer); } glGetIntegerv (GL_READ_BUFFER, &buffer); if (buffer == GL_NONE) { glReadBuffer (GL_BACK); } glBindFramebuffer (GL_READ_FRAMEBUFFER, curReadFB); glBindFramebuffer (GL_DRAW_FRAMEBUFFER, curDrawFB); GL_CHECKPOINT (LOW); } return error ? MakeCurrentResult::Failed : MakeCurrentResult::Succeeded; } Frame SkiaOpenGLPipeline::getFrame () { LOG_ALWAYS_FATAL_IF (mEglSurface == EGL_NO_SURFACE, "drawRenderNode called on a context with no surface!" ); return mEglManager.beginFrame (mEglSurface); } IRenderPipeline::DrawResult SkiaOpenGLPipeline::draw ( const Frame& frame, const SkRect& screenDirty, const SkRect& dirty, const LightGeometry& lightGeometry, LayerUpdateQueue* layerUpdateQueue, const Rect& contentDrawBounds, bool opaque, const LightInfo& lightInfo, const std::vector<sp<RenderNode>>& renderNodes, FrameInfoVisualizer* profiler, const HardwareBufferRenderParams& bufferParams, std::mutex& profilerLock) if (!isCapturingSkp () && !mHardwareBuffer) { mEglManager.damageFrame (frame, dirty); } SkColorType colorType = getSurfaceColorType (); GrGLFramebufferInfo fboInfo; fboInfo.fFBOID = 0 ; if (colorType == kRGBA_F16_SkColorType) { fboInfo.fFormat = GL_RGBA16F; } else if (colorType == kN32_SkColorType) { fboInfo.fFormat = GL_RGBA8; } else if (colorType == kRGBA_1010102_SkColorType) { fboInfo.fFormat = GL_RGB10_A2; } else if (colorType == kAlpha_8_SkColorType) { fboInfo.fFormat = GL_R8; } else { LOG_ALWAYS_FATAL ("Unsupported color type." ); } auto backendRT = GrBackendRenderTargets::MakeGL (frame.width (), frame.height (), 0 , STENCIL_BUFFER_SIZE, fboInfo); SkSurfaceProps props (mColorMode == ColorMode::Default ? 0 : SkSurfaceProps::kAlwaysDither_Flag, kUnknown_SkPixelGeometry) SkASSERT (mRenderThread.getGrContext () != nullptr ); sk_sp<SkSurface> surface; SkMatrix preTransform; if (mHardwareBuffer) { surface = getBufferSkSurface (bufferParams); preTransform = bufferParams.getTransform (); } else { surface = SkSurfaces::WrapBackendRenderTarget (mRenderThread.getGrContext (), backendRT, getSurfaceOrigin (), colorType, mSurfaceColorSpace, &props); preTransform = SkMatrix::I (); } SkPoint lightCenter = preTransform.mapXY (lightGeometry.center.x, lightGeometry.center.y); LightGeometry localGeometry = lightGeometry; localGeometry.center.x = lightCenter.fX; localGeometry.center.y = lightCenter.fY; LightingInfo::updateLighting (localGeometry, lightInfo); renderFrame (*layerUpdateQueue, dirty, renderNodes, opaque, contentDrawBounds, surface, preTransform); if (CC_UNLIKELY (Properties::showDirtyRegions || ProfileType::None != Properties::getProfileType ())) { std::scoped_lock lock (profilerLock) ; SkCanvas* profileCanvas = surface->getCanvas (); SkiaProfileRenderer profileRenderer (profileCanvas, frame.width(), frame.height()) ; profiler->draw (profileRenderer); } { ATRACE_NAME ("flush commands" ); skgpu::ganesh::FlushAndSubmit (surface); } layerUpdateQueue->clear (); if (CC_UNLIKELY (Properties::debugLevel != kDebugDisabled)) { dumpResourceCacheUsage (); } return {true , IRenderPipeline::DrawResult::kUnknownTime, android::base::unique_fd{}}; } bool SkiaOpenGLPipeline::swapBuffers (const Frame& frame, IRenderPipeline::DrawResult& drawResult, const SkRect& screenDirty, FrameInfo* currentFrameInfo, bool * requireSwap) GL_CHECKPOINT (LOW); currentFrameInfo->markSwapBuffers (); if (mHardwareBuffer) { return false ; } *requireSwap = drawResult.success || mEglManager.damageRequiresSwap (); if (*requireSwap && (CC_UNLIKELY (!mEglManager.swapBuffers (frame, screenDirty)))) { return false ; } return *requireSwap; } DeferredLayerUpdater* SkiaOpenGLPipeline::createTextureLayer () { mRenderThread.requireGlContext (); return new DeferredLayerUpdater (mRenderThread.renderState ()); } void SkiaOpenGLPipeline::onContextDestroyed () if (mEglSurface != EGL_NO_SURFACE) { mEglManager.destroySurface (mEglSurface); mEglSurface = EGL_NO_SURFACE; } } void SkiaOpenGLPipeline::onStop () if (mEglManager.isCurrent (mEglSurface)) { mEglManager.makeCurrent (EGL_NO_SURFACE); } } bool SkiaOpenGLPipeline::setSurface (ANativeWindow* surface, SwapBehavior swapBehavior) mNativeWindow = surface; mSwapBehavior = swapBehavior; if (mEglSurface != EGL_NO_SURFACE) { mEglManager.destroySurface (mEglSurface); mEglSurface = EGL_NO_SURFACE; } if (surface) { mRenderThread.requireGlContext (); auto newSurface = mEglManager.createSurface (surface, mColorMode, mSurfaceColorSpace); if (!newSurface) { return false ; } mEglSurface = newSurface.unwrap (); } if (mEglSurface != EGL_NO_SURFACE) { const bool preserveBuffer = (swapBehavior != SwapBehavior::kSwap_discardBuffer); mEglManager.setPreserveBuffer (mEglSurface, preserveBuffer); return true ; } return false ; } [[nodiscard]] android::base::unique_fd SkiaOpenGLPipeline::flush () { int fence = -1 ; EGLSyncKHR sync = EGL_NO_SYNC_KHR; mEglManager.createReleaseFence (true , &sync, &fence); if (sync != EGL_NO_SYNC_KHR) { EGLDisplay display = mEglManager.eglDisplay (); EGLint result = eglClientWaitSyncKHR (display, sync, 0 , 1000000000 ); if (result == EGL_FALSE) { ALOGE ("EglManager::createReleaseFence: error waiting for previous fence: %#x" , eglGetError ()); } else if (result == EGL_TIMEOUT_EXPIRED_KHR) { ALOGE ("EglManager::createReleaseFence: timeout waiting for previous fence" ); } eglDestroySyncKHR (display, sync); } return android::base::unique_fd (fence); } bool SkiaOpenGLPipeline::isSurfaceReady () return CC_UNLIKELY (mEglSurface != EGL_NO_SURFACE); } bool SkiaOpenGLPipeline::isContextReady () return CC_LIKELY (mEglManager.hasEglContext ()); } void SkiaOpenGLPipeline::invokeFunctor (const RenderThread& thread, Functor* functor) DrawGlInfo::Mode mode = DrawGlInfo::kModeProcessNoContext; if (thread.eglManager ().hasEglContext ()) { mode = DrawGlInfo::kModeProcess; } (*functor)(mode, nullptr ); if (mode != DrawGlInfo::kModeProcessNoContext) { thread.getGrContext ()->resetContext (); } } } } }
SkiaOpenGLPipeline 职能 通过 mEglManager.swapBuffers(...) 将绘制好的 Buffer 放入了 BufferQueue。SurfaceFlinger (系统侧): 在下一次 VSync 到来时,感知到 BufferQueue 中有了新数据。合成动作: SurfaceFlinger 将你提交的这个 Buffer,与其他所有可见层(如状态栏)合并。最终显示: 将合成后的结果发给屏幕控制器。
flush commands 耗时监控 ATRACE_NAME 利用了 C++ 的 RAII (Resource Acquisition Is Initialization) 机制。你不需要手动写“开始”和“结束”,它会自动管理生命周期:
执行宏时: 它会在当前作用域创建一个临时的 Trace 对象,内部调用 ATRACE_BEGIN("flush commands"),告诉系统:“我要开始记录了,名字叫 flush commands”。离开作用域时: 当代码执行到该大括号 {} 的末尾,临时对象被销毁,自动调用 ATRACE_END(),告诉系统:“这个动作结束了”。
1 2 3 4 { ATRACE_NAME ("flush commands" ); skgpu::ganesh::FlushAndSubmit (surface); }
这意味着系统会自动计算 FlushAndSubmit 这一行代码到底消耗了多少微秒/毫秒。
COMMAND_ISSUE_DURATION 和 ATRACE_NAME(“flush commands”) 耗时的不同 COMMAND_ISSUE_DURATION 的定义是:从“开始处理绘制指令”到“指令提交完毕”的完整周期。
COMMAND_ISSUE_DURATION = [绘制指令生成 (CPU)] + [FlushAndSubmit (指令提交)]
而 ATRACE_NAME("flush commands") 仅仅覆盖了其中的后半部分:
ATRACE("flush commands") = [仅 FlushAndSubmit 这一步的耗时]
SWAP_BUFFERS_DURATION (将渲染完成的 Buffer 提交给 SurfaceFlinger。) 计时开始 (Start)
在哪里出发: SkiaOpenGLPipeline::swapBuffers() 函数中。动作: 当代码执行到 currentFrameInfo->markSwapBuffers() 这一行时,它会立刻记录下当前的系统时间戳,作为一个“记号”。含义: “计时开始,现在开始进行缓冲区交换。”
计时结束与计算 (End)
在哪里结束: JankTracker::finishFrame() 函数中。动作: 这一帧的所有渲染工作全部完成后,系统会调用这个函数来“结算”这一帧的表现。
底层图形系统 (frameworks/native/libs/gui/) 关键阻塞点:Surface::dequeueBuffer() 该函数在 CanvasContext::draw() 执行过程中被调用(对应源码中的 Frame frame = getFrame(); 这一行 ),用于向 BufferQueue 索要一个可写的图形缓冲区。
阻塞逻辑 : 如果当前所有的 Buffer 都在 SurfaceFlinger 端等待显示,或者 GPU 上一帧还没跑完导致没有空闲 Buffer,渲染线程会在此处挂起。这是全链路中最著名的潜在阻塞点 。监控 : 通过 dumpsys gfxinfo 查看到的 Dequeue Buffer 耗时(或 Trace 中的 DequeueBufferDuration)即代表此处的等待时长。较高的数值通常意味着系统负载极重、SurfaceFlinger 合成压力大或 GPU 性能达到瓶颈。
JankTracker 源代码(Android 15) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 318 319 320 321 322 323 324 325 326 327 328 329 330 331 332 333 334 335 336 337 338 339 340 341 342 343 344 345 346 347 348 349 350 351 #include "JankTracker.h" #include <cutils/ashmem.h> #include <cutils/trace.h> #include <errno.h> #include <inttypes.h> #include <log/log.h> #include <algorithm> #include <cmath> #include <cstdio> #include <limits> #include <sstream> #include "DeviceInfo.h" #include "Properties.h" #include "utils/TimeUtils.h" #include "utils/Trace.h" namespace android {namespace uirenderer {struct Comparison { JankType type; std::function<int64_t (nsecs_t )> computeThreadshold; FrameInfoIndex start; FrameInfoIndex end; }; static const std::array<Comparison, 4> COMPARISONS{ Comparison{JankType::kMissedVsync, [](nsecs_t ) { return 1 ; }, FrameInfoIndex::IntendedVsync, FrameInfoIndex::Vsync}, Comparison{JankType::kSlowUI, [](nsecs_t frameInterval) { return static_cast <int64_t >(.5 * frameInterval); }, FrameInfoIndex::Vsync, FrameInfoIndex::SyncStart}, Comparison{JankType::kSlowSync, [](nsecs_t frameInterval) { return static_cast <int64_t >(.2 * frameInterval); }, FrameInfoIndex::SyncStart, FrameInfoIndex::IssueDrawCommandsStart}, Comparison{JankType::kSlowRT, [](nsecs_t frameInterval) { return static_cast <int64_t >(.75 * frameInterval); }, FrameInfoIndex::IssueDrawCommandsStart, FrameInfoIndex::FrameCompleted}, }; static const int64_t IGNORE_EXCEEDING = seconds_to_nanoseconds (10 );static const int64_t EXEMPT_FRAMES_FLAGS = FrameInfoFlags::SurfaceCanvas;static FrameInfoIndex sFrameStart = FrameInfoIndex::IntendedVsync;JankTracker::JankTracker (ProfileDataContainer* globalData) : mData (globalData->getDataMutex ()) , mDataMutex (globalData->getDataMutex ()) { mGlobalData = globalData; nsecs_t frameIntervalNanos = DeviceInfo::getVsyncPeriod (); nsecs_t sfOffset = DeviceInfo::getCompositorOffset (); nsecs_t offsetDelta = sfOffset - DeviceInfo::getAppOffset (); if (offsetDelta <= 4 _ms && offsetDelta >= 0 ) { mDequeueTimeForgivenessLegacy = offsetDelta + 4 _ms; } mFrameIntervalLegacy = frameIntervalNanos; } void JankTracker::calculateLegacyJank (FrameInfo& frame) REQUIRES (mDataMutex) int64_t totalDuration = frame.duration (sFrameStart, FrameInfoIndex::SwapBuffersCompleted); if (mDequeueTimeForgivenessLegacy && frame[FrameInfoIndex::DequeueBufferDuration] > 500 _us) { nsecs_t expectedDequeueDuration = mDequeueTimeForgivenessLegacy + frame[FrameInfoIndex::Vsync] - frame[FrameInfoIndex::IssueDrawCommandsStart]; if (expectedDequeueDuration > 0 ) { nsecs_t forgiveAmount = std::min (expectedDequeueDuration, frame[FrameInfoIndex::DequeueBufferDuration]); if (forgiveAmount >= totalDuration) { ALOGV ("不可能的出队耗时! reported %" PRId64 ", total %" PRId64, forgiveAmount, totalDuration); return ; } totalDuration -= forgiveAmount; } } if (totalDuration <= 0 ) { ALOGV ("总时长异常 %" PRId64 " start=%" PRIi64 " gpuComplete=%" PRIi64, totalDuration, frame[FrameInfoIndex::IntendedVsync], frame[FrameInfoIndex::GpuCompleted]); return ; } if (CC_UNLIKELY (frame[FrameInfoIndex::Flags] & EXEMPT_FRAMES_FLAGS)) { return ; } if (totalDuration > mFrameIntervalLegacy) { mData->reportJankLegacy (); (*mGlobalData)->reportJankLegacy (); } if (mSwapDeadlineLegacy < 0 ) { mSwapDeadlineLegacy = frame[FrameInfoIndex::IntendedVsync] + mFrameIntervalLegacy; } bool isTripleBuffered = (mSwapDeadlineLegacy - frame[FrameInfoIndex::IntendedVsync]) > (mFrameIntervalLegacy * 0.1 ); mSwapDeadlineLegacy = std::max (mSwapDeadlineLegacy + mFrameIntervalLegacy, frame[FrameInfoIndex::IntendedVsync] + mFrameIntervalLegacy); if (frame[FrameInfoIndex::FrameCompleted] < mSwapDeadlineLegacy || totalDuration < mFrameIntervalLegacy) { if (isTripleBuffered) { mData->reportJankType (JankType::kHighInputLatency); (*mGlobalData)->reportJankType (JankType::kHighInputLatency); } return ; } mData->reportJankType (JankType::kMissedDeadlineLegacy); (*mGlobalData)->reportJankType (JankType::kMissedDeadlineLegacy); nsecs_t jitterNanos = frame[FrameInfoIndex::FrameCompleted] - frame[FrameInfoIndex::Vsync]; nsecs_t lastFrameOffset = jitterNanos % mFrameIntervalLegacy; mSwapDeadlineLegacy = frame[FrameInfoIndex::FrameCompleted] - lastFrameOffset + mFrameIntervalLegacy; } void JankTracker::finishFrame (FrameInfo& frame, std::unique_ptr<FrameMetricsReporter>& reporter, int64_t frameNumber, int32_t surfaceControlId) std::lock_guard lock (mDataMutex) ; calculateLegacyJank (frame); int64_t totalDuration = frame.duration (FrameInfoIndex::IntendedVsync, FrameInfoIndex::FrameCompleted); if (totalDuration <= 0 ) { ALOGV ("总时长异常 %" PRId64, totalDuration); return ; } mData->reportFrame (totalDuration); (*mGlobalData)->reportFrame (totalDuration); if (CC_UNLIKELY (frame[FrameInfoIndex::Flags] & EXEMPT_FRAMES_FLAGS)) { return ; } int64_t frameInterval = frame[FrameInfoIndex::FrameInterval]; bool isTripleBuffered = (mNextFrameStartUnstuffed - frame[FrameInfoIndex::IntendedVsync]) > (frameInterval * 0.1 ); int64_t deadline = frame[FrameInfoIndex::FrameDeadline]; if (isTripleBuffered) { int64_t originalDeadlineDuration = deadline - frame[FrameInfoIndex::IntendedVsync]; deadline = mNextFrameStartUnstuffed + originalDeadlineDuration; frame.set (FrameInfoIndex::FrameDeadline) = deadline; } if (frame[FrameInfoIndex::GpuCompleted] < deadline) { if (isTripleBuffered) { mData->reportJankType (JankType::kHighInputLatency); (*mGlobalData)->reportJankType (JankType::kHighInputLatency); mNextFrameStartUnstuffed += frameInterval; } } else { mData->reportJankType (JankType::kMissedDeadline); (*mGlobalData)->reportJankType (JankType::kMissedDeadline); mData->reportJank (); (*mGlobalData)->reportJank (); nsecs_t jitterNanos = frame[FrameInfoIndex::GpuCompleted] - frame[FrameInfoIndex::Vsync]; nsecs_t lastFrameOffset = jitterNanos % frameInterval; mNextFrameStartUnstuffed = frame[FrameInfoIndex::GpuCompleted] - lastFrameOffset + frameInterval; recomputeThresholds (frameInterval); for (auto & comparison : COMPARISONS) { int64_t delta = frame.duration (comparison.start, comparison.end); if (delta >= mThresholds[comparison.type] && delta < IGNORE_EXCEEDING) { mData->reportJankType (comparison.type); (*mGlobalData)->reportJankType (comparison.type); } } if (totalDuration >= 700 _ms) { static int sDaveyCount = 0 ; std::stringstream ss; ss << "Davey! duration=" << ns2ms (totalDuration) << "ms; " ; for (size_t i = 0 ; i < static_cast <size_t >(FrameInfoIndex::NumIndexes); i++) { ss << FrameInfoNames[i] << "=" << frame[i] << ", " ; } ALOGI ("%s" , ss.str ().c_str ()); ATRACE_INT (ss.str ().c_str (), ++sDaveyCount); } } int64_t totalGPUDrawTime = frame.gpuDrawTime (); if (totalGPUDrawTime >= 0 ) { mData->reportGPUFrame (totalGPUDrawTime); (*mGlobalData)->reportGPUFrame (totalGPUDrawTime); } if (CC_UNLIKELY (reporter.get () != nullptr )) { reporter->reportFrameMetrics (frame.data (), false , frameNumber, surfaceControlId); } } void JankTracker::recomputeThresholds (int64_t frameBudget) REQUIRES (mDataMutex) if (mThresholdsFrameBudget == frameBudget) { return ; } mThresholdsFrameBudget = frameBudget; for (auto & comparison : COMPARISONS) { mThresholds[comparison.type] = comparison.computeThreadshold (frameBudget); } } void JankTracker::dumpData (int fd, const ProfileDataDescription* description, const ProfileData* data) #ifdef __ANDROID__ if (description) { switch (description->type) { case JankTrackerType::Generic: break ; case JankTrackerType::Package: dprintf (fd, "\nPackage: %s" , description->name.c_str ()); break ; case JankTrackerType::Window: dprintf (fd, "\nWindow: %s" , description->name.c_str ()); break ; } } if (sFrameStart != FrameInfoIndex::IntendedVsync) { dprintf (fd, "\nNote: Data has been filtered!" ); } data->dump (fd); dprintf (fd, "\n" ); #endif } void JankTracker::dumpFrames (int fd) #ifdef __ANDROID__ dprintf (fd, "\n\n---PROFILEDATA---\n" ); for (size_t i = 0 ; i < static_cast <size_t >(FrameInfoIndex::NumIndexes); i++) { dprintf (fd, "%s" , FrameInfoNames[i]); dprintf (fd, "," ); } for (size_t i = 0 ; i < mFrames.size (); i++) { FrameInfo& frame = mFrames[i]; if (frame[FrameInfoIndex::SyncStart] == 0 ) { continue ; } dprintf (fd, "\n" ); for (int i = 0 ; i < static_cast <int >(FrameInfoIndex::NumIndexes); i++) { dprintf (fd, "%" PRId64 "," , frame[i]); } } dprintf (fd, "\n---PROFILEDATA---\n\n" ); #endif } void JankTracker::reset () REQUIRES (mDataMutex) mFrames.clear (); mData->reset (); (*mGlobalData)->reset (); sFrameStart = Properties::filterOutTestOverhead ? FrameInfoIndex::HandleInputStart : FrameInfoIndex::IntendedVsync; } } }